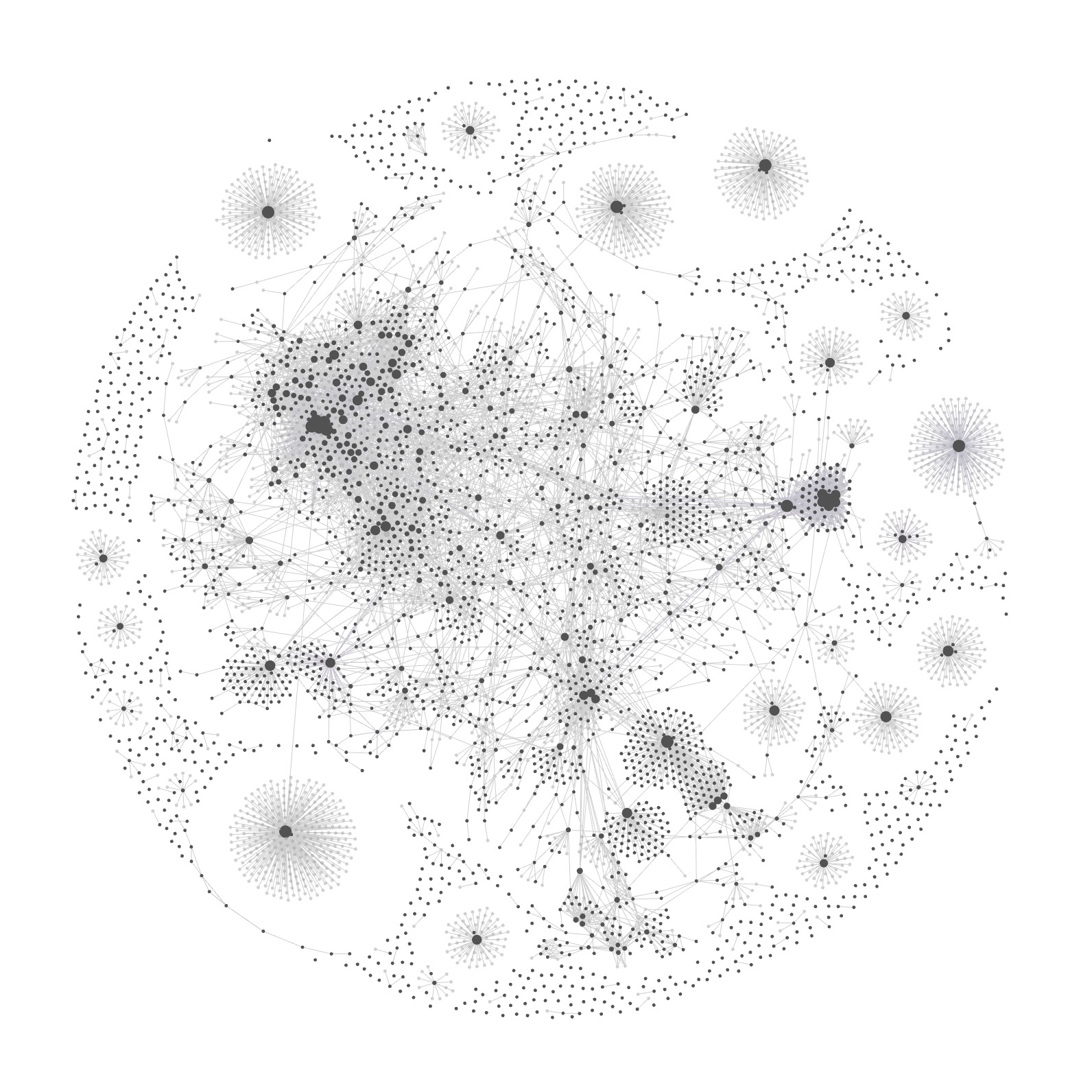
我从 2023 年开始用 Obsidian 整理知识笔记,至今约两年。目前知识库有近 3000 条笔记,这是除了我的大脑之外的一个强大外脑:只要是我学习过并且认为会终身受用的知识,我都会创建一条知识笔记。
一开始选择用 Obsidian 作为知识笔记管理工具,有以下原因:
-
笔记格式全部为 markdown,并且本地储存。记录过程流畅、专注于内容,而不需要反复调整样式;体积小、不占空间,也不用担心云服务器突然关停或离线无法操作。
-
支持内链。做笔记时,除了将参考资料的外链作为索引,更重要的是让笔记之间建立语义关联。因为知识体系本质上是一个网络:链接越多、越密集,学习、思考和推理的速度就越快。
-
笔记模板。我用统一模板 2w2h 来记录,确保每条笔记都能反映“来龙去脉 / 是什么 / 为什么 / 怎么做”。
但当笔记越来越多,就出现了问题:
- 关键词搜索时常找不到。比如我最近看《卓有成效的管理者》中提到“反面意见”,我想到《原则》也多次出现这个观点,但无论怎么搜都搜不到——因为记不起来《原则》里对应的原词是什么,而且分散在多个章节。
- 内链利用率低。除了写笔记时顺手加几条,平时检索时很少真正发挥“跨笔记联想”的价值。
在 AI 覆盖生活的方方面面的同时,个人知识库也需要一种全新的方式来管理和调用,让“知识之间的语义关联”真正得到体现。在这里,我推荐 Obsidian 插件——Smart Connections。
什么是 Smart Connections
它是 Obsidian 的语义联想 / 检索插件:会给你的笔记做向量索引(embeddings),然后按“语义相似度”而不是关键词去找“看起来相关”的卡片。它的 Smart Chat 还能在库内做聊天问答(RAG:检索增强生成)、自动给出链接/标签建议、生成摘要与问题清单。
什么是 embeddings(嵌入)?
把自然语言切分为 token(词元),再映射成高维数字向量,放入一个语义空间里;在这个空间中,语义越接近的文本,向量距离越近,因此可以更像人脑那样“按意思”找资料,而不是死盯关键词。
什么是 RAG?
对你的 Obsidian 本地知识库进行向量检索,并将检索到的内容作为上下文输入给 LLM,然后生成答案。RAG 的检索,本质上是在理解语义的情况下进行的搜索,是语义层面的匹配。而不是单纯的搜索引擎式的「关键词」匹配。
如何安装
安装 Smart Connections
设置 → Community Plugins(社区插件)→ 关闭 Restricted mode(受限模式)→ 搜索 Smart Connections 并安装、启用。
选择模型后端
- Smart Connections 里分成两类模型:嵌入(Embeddings)与聊天(Chat)。
- 嵌入(Embeddings)用于建索引与相似度检索:
- 本地(默认,内置 / built-in):插件自带基于 transformers.js 的本地向量引擎,下载好模型后可断网使用。中文库建议:
jina-embeddings-v2-base-zh(≈8K tokens,上下文更从容,中文表现稳定)- 或
bge-micro-v2(轻量开箱、性能要求更低)
- 远程(OpenAI 生态):选择 OpenAI 或 OpenAI-兼容端点(如 Azure / OpenRouter)提供的嵌入模型,例如
text-embedding-3-small/large(效果强、需 API 费用)。
- 本地(默认,内置 / built-in):插件自带基于 transformers.js 的本地向量引擎,下载好模型后可断网使用。中文库建议:
- 聊天(Chat)用于 Smart Chat 回答生成:
- 本地:Ollama / LM Studio 等(隐私好、零成本,效果视机型和模型而定)。
- 云端:OpenAI、Claude、Gemini、DeepSeek 等。DeepSeek Reasoner非常够用,可到DeepSeek 开放平台获取 API Key。
- 嵌入(Embeddings)用于建索引与相似度检索:
建索引
- 初次安装后,插件会对全库自动嵌入与索引;看到系统通知 “Embedding complete” 就能开始使用。
- 需要重建时,在命令面板运行 Smart Connections: Rebuild embeddings(库很大时首次会慢些,此后为增量更新)。
- 索引存放位置:默认写在你的库根目录
.smart-env/multi/;插件本体在.obsidian/plugins/smart-connections。删除索引目录会触发重建。
开始用(Connections 面板)
- 在任意笔记右侧打开 Connections 面板,查看 Related notes:按相似度排序的相关卡片。相似度分数越接近 1,语义越相近。
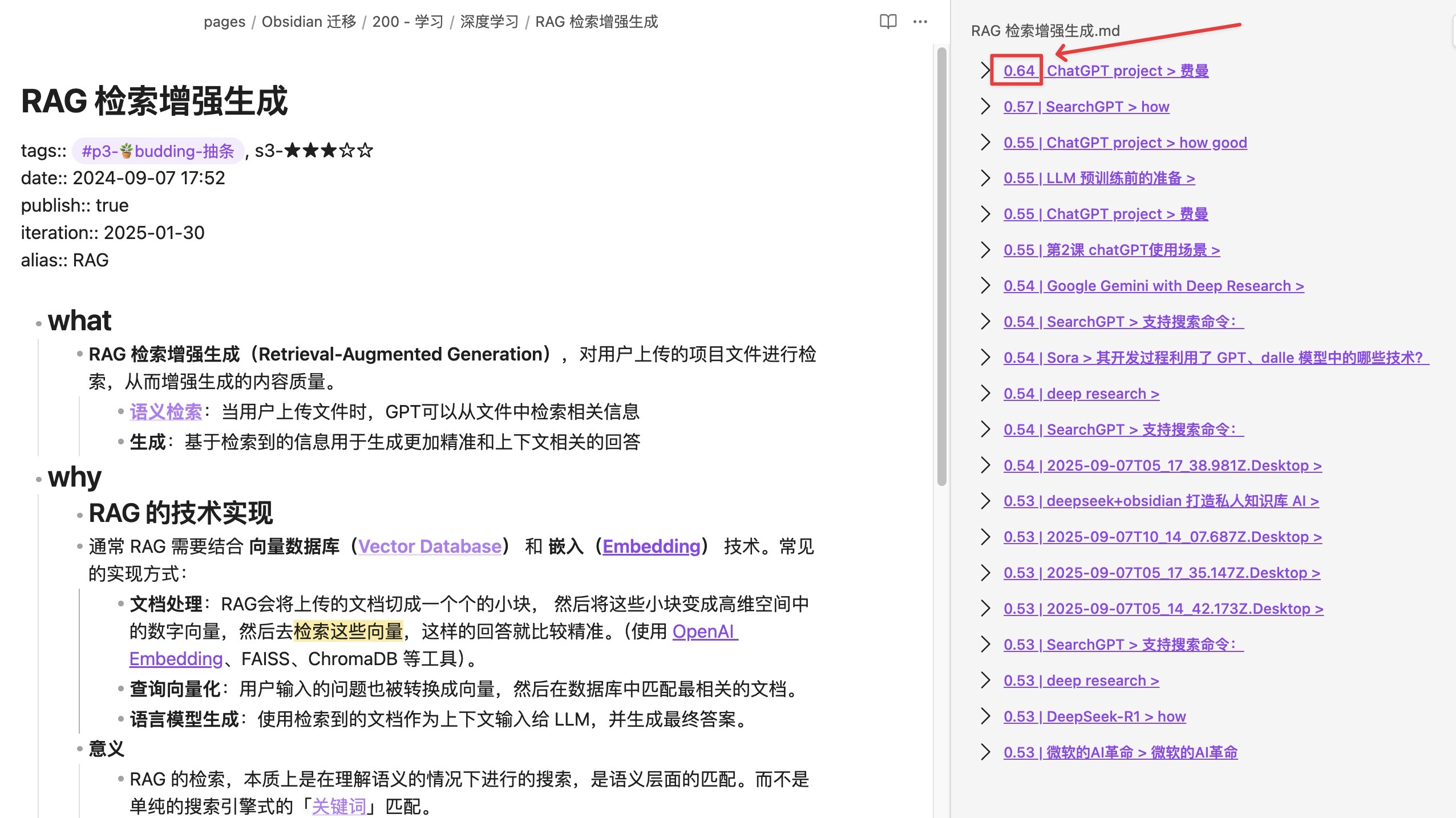
配置Smart Chat(库内 RAG 问答)
-
配置:插件设置里选择聊天模型(可用 DeepSeek Reasoner 等)→ 添加 API Key(可在DeepSeek 开放平台获取,或使用 OpenRouter 等 OpenAI-兼容端点)。
-
使用技巧:
- 在提问中加入“基于我的笔记 / based on my notes”提示,Smart Chat 会先检索相关块再回答。
- 用 @ 文件名 直接点名某条笔记作为上下文。
- 善用自动链接/标签建议、摘要与问题清单,把一次问答变成“复盘—回写”的闭环。

AI 时代,为什么更需要知识管理?
随着 AI 大模型的快速发展,当下的 AI 已经阅读并理解了几乎所有公开的人类知识,我们自己再去费力地记忆和整理知识,是否还有意义?
有意义,且更有意义,AI 时代才更需要我们建立属于自己的知识体系。
AI 消除了信息优势,知识管理转向个体深度整合
过去我们可以靠掌握某种独特信息或技能,就拥有相对竞争优势;然而今天,ChatGPT 等 AI 工具迅速拉平了这种优势。
在知识变得“廉价而易得”的环境下,竞争的重心不再是你知道多少知识,而是你能否快速整合、重构知识,并且在面对新问题时迅速调用、迁移与应用这些知识。换句话说,知识管理从过去的信息积累,转向了整合与应用的能力。
外脑的本质是增强人脑,而非取代人脑
ChatGPT 等大语言模型能帮我们快速地从庞杂的信息中找到答案;但 AI 始终缺乏一个关键要素:个体语境(personal context)。你的职业、生活、兴趣和过去经历,决定了你关注的信息与知识构成,而这些是 AI 无法替代的。
而个人知识库(例如用 Obsidian、logseq 等工具构建),本质上是学习、思考、经历的外在投射,是我们大脑的一种延伸。当 AI 与你的私人知识库结合时,这种“增强版外脑”能够真正发挥作用,帮助我们高效地解决问题。
AI 是启发工具,深刻的思考依旧来自个人知识体系
与 AI 互动的过程中,通常会经历这样几个阶段:
-
探索阶段:当首次接触一个陌生领域时,可以借助 AI 快速建立初步认知框架。
-
深化阶段:随后,需要将学到的内容记录下来,并建立自己的知识体系,以方便日后随时调用。
-
应用阶段:遇到新问题时,需要迅速从自己的知识库中调出已有知识,与新情境结合,迅速作出判断和决策。
AI增强了第一个环节——快速探索与初步认知,而接下来的实际应用与反馈,更加依赖的是自己所构建的知识体系。
建立知识体系的过程也是锻炼“深层次思考能力”的过程
为什么一定要自己动手整理知识体系,而不是简单依赖 AI 问答?原因在于:
构建知识体系本身即是一种深度学习行为,这个过程中,你的大脑需要主动提炼、总结、分类、链接信息,这正是高阶思考能力——分析、归纳、推演能力——的训练方式。
每次调用知识库,都是一次对个人知识结构的复盘与检验,强化对知识的深刻理解,也让你更敏锐地察觉到知识间的关联、冲突、空白与机会。
而正是对知识的深刻理解与主动调用,才能在解决实际问题时迅速应对。
知识库+AI:形成个人竞争力的复利效应
每个人的知识体系就像一个私域语境(Private Context)。AI 模型能回答绝大部分通用问题,但只有你的知识库能深刻反映你的思考方式与关注点。
当你用 Smart Connections、Smart Chat 等工具时,能快速从庞大的知识库中,按语义关联而非关键词,找到最相关的知识笔记;
AI 又基于你自己的知识库内容,给出个性化的答案,帮助你更高效、更精准地解决问题;
这种调用和反馈又会不断强化你的知识体系,让你未来调用知识的过程更加流畅、高效。
长此以往,你的知识库不断变得更加精准有效,AI 与你的互动效率也不断提升,从而形成个人知识管理的复利效应,这种复利效应是传统的“随手记录笔记”不能比拟的。
总结与启发
AI 的普及,带来的并非知识管理的弱化,反而是对我们每个人建立个人知识管理体系的更高要求。
-
过去靠信息优势,现在靠知识整合与迁移能力;
-
AI 强在启发,而思考和深度学习依靠的是个人知识体系;
-
知识管理不仅管理知识,更是在锻炼你的思考与判断能力;
-
个人知识体系与 AI 结合形成个人效率与洞察力的复利。
因此,在 AI 时代,打造一个真正属于你自己的、持续进化的知识体系,才是你能获得长期竞争力的关键所在。