我们常常陷入一种悖论:你明明没想刷手机,手却自动伸向了口袋;你明明不饿,深夜却还是打开了零食柜。
大多数时候,我们以为自己在做决定,但实际上,我们只是在一遍又一遍地运行“预录好”的脚本。这并非意志上的薄弱,也不是道德上的堕落,而是大脑的聪明设计:节能。既然如此,这种不由自主的习惯是如何在大脑中形成并自动化的?这种省力模式与 AlphaZero 在棋局中选择性搜索有何异曲同工?更重要的是,坏习惯既然不受大脑“前台”监管,我们要怎样识别并改变它们?苏格拉底曾说“未经审视的生活不值得过”,这句话或许正道出了破解之道。
两种智能模式:直觉 vs 模拟
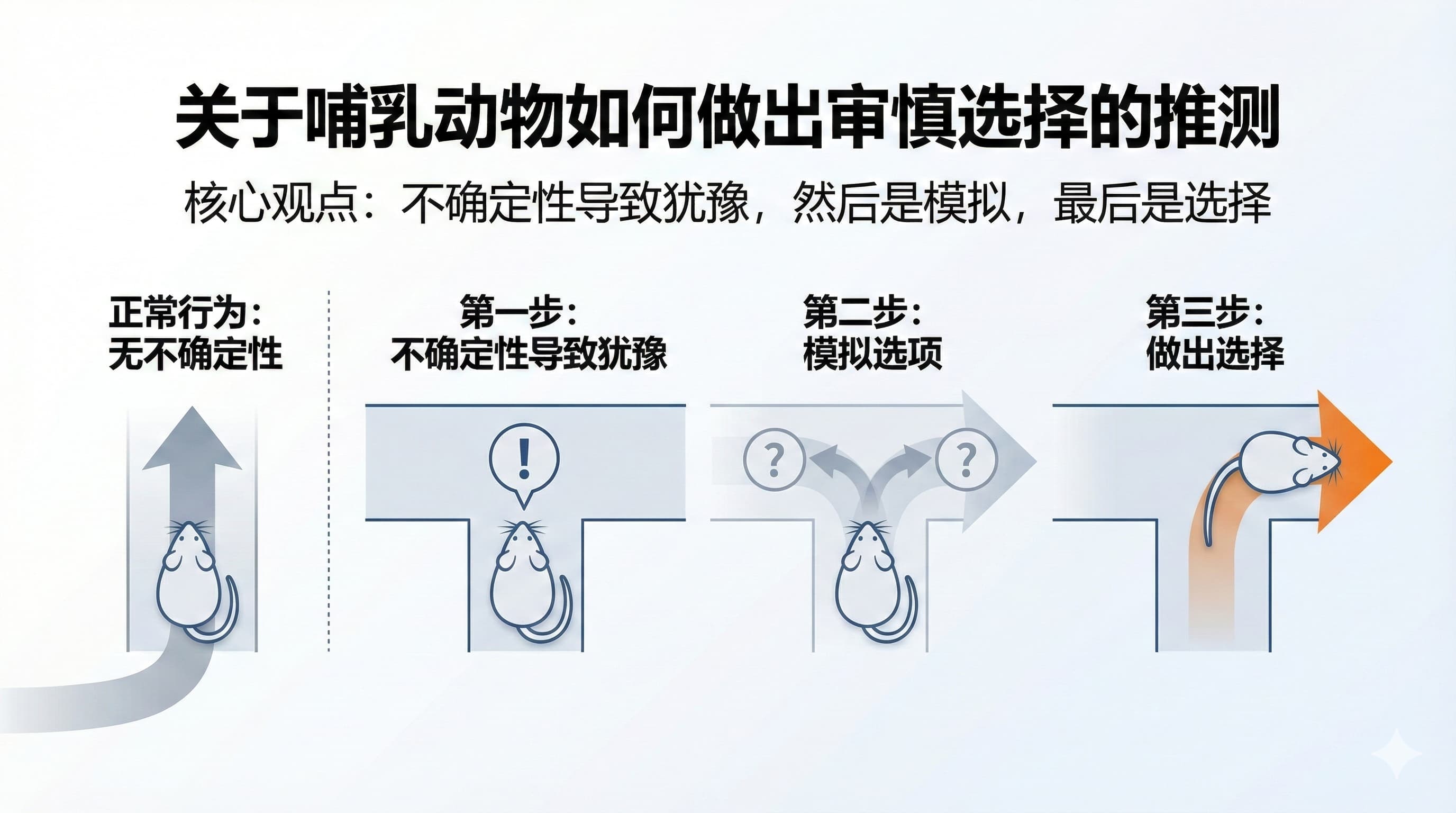
要理解习惯的机制,我们先看两种决策模式:一种是直觉反应,凭经验值直接行动;另一种是模拟推演,在脑海中预演后果再做选择。
人工智能的两种范式
在人工智能领域类似地有无模型(model-free)策略和有模型(model-based)策略。前者不进行内部推演,只根据积累的经验价值直接决策;后者则会在行动前模拟未来情境再决定。比如早期一些棋类 AI 完全凭经验评分走棋,而 AlphaZero 这类 AI 会在每一步落子前模拟大量可能走法,选出胜率最高的一着。
| 特性 | 无模型强化学习 (Model-Free RL) | 基于模型的强化学习 (Model-Based RL) |
|---|---|---|
| 代表案例 | TD-Gammon (类似西洋双陆棋 AI) | AlphaZero (围棋/国际象棋 AI) |
| 运作方式 | 时序差分学习。只看当前的局面,凭“感觉”直接反应。 | 内部模拟。在行动前,先在脑海中“推演”未来的可能性。 |
| 生物对应 | 旧脑/基底神经节 (本能、习惯) | 新皮质/前额叶 (规划、推理) |
| 核心差异 | 不需要了解世界如何运作,只需试错。 | 学习一个世界模型,了解行动如何影响世界。 |
大脑中的对应系统
人类大脑同样有这两套系统。一方面,基底神经节等结构就像经验驱动的“自动驾驶仪”,在熟悉情境下以高速低耗方式执行习惯化动作。另一方面,前额叶皮质负责有意识的深度思考和计划,但它运转耗能高、容易疲劳。因此,大脑倾向让习惯系统处理常规事务,只有遇到新情况或冲突时才调用前额叶接管“手动驾驶”。
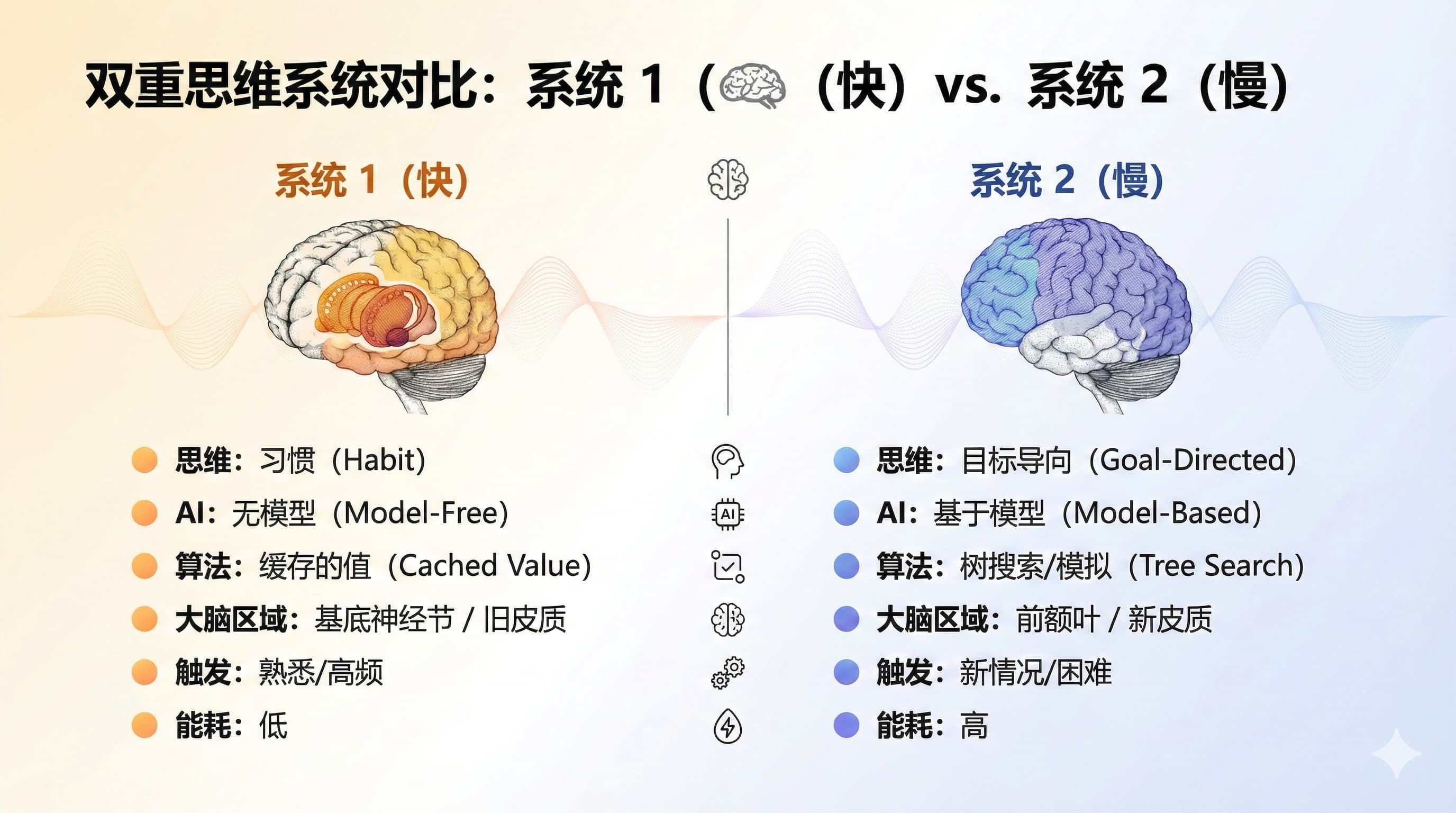
| 维度 | 系统 1 (快) | 系统 2 (慢) |
|---|---|---|
| 思维模式 | 习惯 (Habit) | 目标导向 (Goal-Directed) |
| AI 类型 | 无模型 (Model-Free) | 基于模型 (Model-Based) |
| 核心算法 | 缓存的值 (Cached Value) | 树搜索/模拟 (Tree Search) |
| 大脑区域 | 基底神经节 / 旧皮质 | 前额叶 / 新皮质 |
| 触发条件 | 熟悉环境、高频重复 | 遇到新情况、预测误差、困难 |
| 能耗 | 低 | 高 (容易疲劳) |
习惯如何建立:从用脑到自动
习惯的起点:刻意的目标导向行为
每个习惯最初都是需要费脑的。有了明确目的,我们往往经过认真思考才采取行动——这是目标导向的刻意行为。彼时前额叶投入大量注意力规划步骤、预测结果。如果行动带来满意的奖励,大脑就会记住这种选择。
重复与缓存:前额叶逐渐退出
接下来,通过重复,大脑开始将行为过程逐步移交给自动系统。就像电脑缓存常用数据一样,多次强化后,特定情境下某动作的“价值”被存储起来。再遇到类似情境时,无需前额叶费心计算,基底神经节直接调用这个“经验方案”执行。换言之,原本需要刻意抉择的行为,逐渐变成了条件反射式的自动反应。
感知钝化:坏习惯变成“不被看见”的行为
一旦行为自动化,我们对它的觉察就降低了。习惯在运行时,只要没有明显错误,大脑不会主动审视它是否合理。即使环境或目标已改变,我们也常常浑然不觉。习惯一旦养成,我们往往沿用旧模式自动驾驶,而忽略情境已变,需要及时调整方向。
大脑的节能策略:向 AlphaZero 学习
模拟思考很烧能量
前额叶的深度思考能力代价高昂:每次在脑中模拟方案、权衡选项,都消耗大量注意力和能量。如果事无巨细都用前额叶,人早就被“烧脑”烧垮了。所以大脑遵循节能原则:非必要不启动耗能的模拟系统。多数情况下由省力的习惯系统当家,只有在重要关头才调用“计算”资源。
AlphaZero 的启示:关键时刻才搜索
围棋的变化量高达 10^17万亿种,如果 AlphaZero 试图计算每一步的所有可能性(全量模拟),用超级计算机也要计算 100 万年。因此,AlphaZero 下棋并非穷举万法,而是借助神经网络预选少数最有希望的招法(1000 种),再集中算力深入分析。也就是说,它大多数时候凭直觉走棋,只有局面复杂难料时才动脑深算。我们的大脑也是类似:平时由习惯应对,碰到情况复杂不确定时,前额叶才跳出来审思。
坏习惯为什么难以察觉
坏习惯之所以顽固,是因为它们巧妙地避开了前额叶的监管机制。前面提到了,前额叶通常只有在检测到“预测误差”(Prediction Error)时才会介入。也就是说,只有当现实与你的预期不符时,大脑才会惊醒:“等一下,好像不对劲。”
坏习惯的可怕之处在于:它往往没有即时的预测误差。 你刷短视频,预期是获得即时快感,实际上你也确实获得了。 你熬夜,预期是获得片刻安宁,实际上你也确实获得了。
至于长期的恶果(复利损失),那是未来的事。当下的预测与结果完全吻合。因此,前额叶判定:一切正常,继续执行。
这就是为什么我们不仅要有习惯,还需要“审视”。
”未经审视的人生不值一提“
两千年前,苏格拉底说:“未经审视的人生不值一提。”(The unexamined life is not worth living.)
在神经科学和算法的语境下,这句话有了全新的含义:未经审视的人生,就是全盘由 Model-Free(习惯系统)托管的人生。
如果你不审视,你就是一台仅仅依赖缓存数据运行的机器。你的喜怒哀乐、你的偏见、你的反应,都是过去经验的简单重演。
例如,父母的教育方式,有时是带着上一代人的创伤的,比如打骂、贬低或是冷暴力。很多父母在被孩子激怒的那一瞬间,会下意识地吼叫甚至动手。其实,他们不想这样,但那一刻,基底神经节接管了身体,播放了他们童年时从父母那里录制的“缓存脚本”。如果父母不去反思这个问题,伤害就会自动遗传给下一代。

所谓的“审视”,本质上是一种人为安装的触发器。
既然坏习惯不会自动触发“预测误差”,我们就必须通过主动思考,强行制造“冲突”。我们需要强行插入一个断点,强迫前额叶启动。
如何发现并改变坏习惯
我们要想“唤醒”前额叶来审视习惯,必须人为制造“预测误差”(Prediction Error) 或者 强行引入“模拟机制”。
1. “逆向工程法”:从结果倒推,做复盘
前额叶虽然不管过程,但它负责处理结果。当习惯处于“自动驾驶”时,我们感觉不到异常,但结果会诚实地积累。
原理:利用前额叶的“逻辑分析”能力,去检查那些让你感到“不舒服、不满意”的现状。
如何做:不要试图监控你的每一分钟(太累了,前额叶做不到),而是定期做复盘:
-
“我最近总是觉得累。”(现状)
-
倒推:我是不是睡太晚了?
-
抓捕习惯:原来我每晚睡前都会无意识地刷 30 分钟视频。(哪怕当时你觉得很爽,但“累”这个预测误差是真实的)。
-
做出改变
2. “人为制造摩擦”:破坏流畅感
习惯之所以能绕过前额叶,是因为 “环境线索”太顺畅了。
原理:只有当“预测”和“现实”不一致,或者遇到困难时,前额叶才会启动“模拟”。所以我们可以故意制造“困难”。
如何做:
-
坏习惯隐形时:把手机充电器放到另一个房间;把零食锁在需要钥匙的柜子里;把浏览器的“自动登录”取消。
-
效果:当你下意识伸手拿手机却摸了个空(预测误差),或者需要输密码觉得麻烦(阻力),基底神经节的自动化流程就被打断了。
-
觉醒时刻:就在那一瞬间,你的前额叶会被强制唤醒:“诶?我为什么要拿手机?我现在真的需要看吗?” —— 这就是你审视它的机会。
3. 语言的介入
日本铁路系统的员工在工作时会用手指着信号灯大喊“信号确认,绿灯!”(指差确认)。这看起来很傻,但极度有效。
原理:语言是前额叶的高级功能。当你被迫把一个动作“说出来”时,你就无法通过基底神经节“无脑”执行它。你必须调用皮层来处理语言。
如何做:
-
当你发现自己可能陷入某种坏习惯(比如吃垃圾食品、刷短视频)的征兆时,强迫自己大声说出(或在心里默念)你正在做的事和它的后果。
-
“我现在要拿起手机刷短视频了,虽然我本来计划看书。这样做会让我半小时后感到空虚。”
-
效果:大声说出来相当于把潜意识的动作显性化了,把它拉到了前额叶的聚光灯下。这时才有机会根据“意图”说不。